




개인정보보호위원회가 생성형 인공지능(AI) 서비스를 개발·활용하는 기업·기관을 위한 개인정보 안전 처리 기준을 마련했다고 6일 밝혔다.
개인정보위는 이날 서울 중구 소재 정동 1928 아트센터에서 ‘생성형 AI와 프라이버시’ 오픈 세미나를 개최하고 ‘생성형 AI 개발·활용을 위한 개인정보 처리 안내서’를 공개했다. 개인정보위는 안내서가 생성형 인공지능 개발과 활용의 전 과정에서 개인정보 보호법 적용의 불확실성을 해소하고, 기업·기관의 자율적 법준수 역량을 높이는 데 큰 역할을 할 것으로 보고 있다. 예를 들어 챗GPT 등 상용 대규모언어모델(LLM) 서비스를 활용해 서비스를 개발·제공하는 사업자 등이 이번 안내서를 활용할 수 있다.
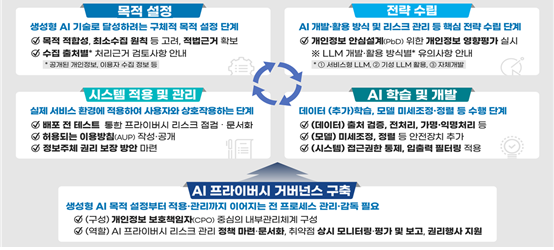
개인정보위가 이번 안내서에서 중점을 둔 부분은 크게 세가지다. 첫째로 생성형 AI를 개발·활용하는 생애주기를 4단계로 분류하고 단계별로 확인할 최소한의 안전조치를 체계적으로 제시했다. 예컨대 목적 설정 단계에서는 목적 적합성, 최소 수집 원칙 등을 고려해 개인정보 수집에 따른 적법 근거를 확보하는 것이 중요하다. 개인정보위는 또한 AI 시스템이 실제로 개발·활용되는 방식과 맥락을 유형화하고, 각 유형에 따른 법적 기준과 안전성 확보 기준을 제시했다.
아울러 개인정보위는 이번 안내서에 이용자 개인정보를 AI에 학습할 수 있는 법적 기준 등 개발·활용 과정에서 불확실성이 높은 이슈들에 대해 개인정보위의 정책 및 집행 사례를 바탕으로 구체적인 해결방안을 제시했다.
이 외에도 AI 에이전트(비서), 지식증류, 머신 언러닝 등 생성형 AI 개발·활용과 관련한 최신 기술 동향과 연구 성과 등을 반영했다. 안내서는 향후 급속한 기술 발전과 국내·외 개인정보 보호 정책 변화에 발맞춰 지속적으로 업데이트될 예정이다.
고학수 개인정보위 위원장은 “명확한 안내서를 통해 실무 현장의 법적 불확실성이 해소되고, 생성형 AI 개발·활용에 개인정보 보호 관점이 체계적으로 반영될 수 있을 것으로 기대된다”며 “앞으로도 개인정보위는 ‘프라이버시’와 ‘혁신’ 두 가치가 상호 공존할 수 있도록 정책 기반을 마련해 나가겠다”고 말했다.
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >
 hoje@sedaily.com
hoje@sedaily.com






































