인공지능(AI) 모델의 성능 한계를 분업 시스템으로 극복하는 신기술 ‘전문가혼합(MoE)’ 모델 개발에 국내 주요 기업들이 앞다퉈 나서고 있다. 모델 크기를 무작정 키우는 대신 작지만 분야별 전문성을 가진 모델들을 합쳐 작업을 효율화하는 기술이다. 올 초 딥시크 열풍을 계기로 중국에서 집중 개발되는 가운데 소버린(자립형) AI를 내세운 국내 기업들도 경쟁력 확보를 위해 관련 대응에 나선 것이다.
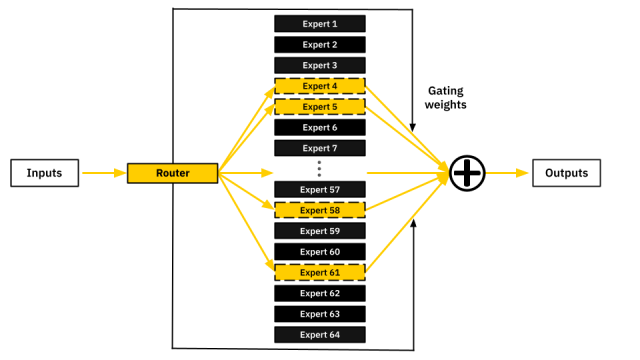
28일 정보기술(IT) 업계에 따르면 SK텔레콤은 ‘에이닷엑스(A.X) MoE’ 모델 공개를 목표로 관련 연구개발(R&D)을 진행 중이다. 최근 선보인 에이닷엑스 3.1과 4.0에 이어 MoE 모델도 자체 개발하겠다는 것이다. MoE는 분야별로 특화한 작은 모델, 이른바 ‘전문가’들을 합쳐 하나의 AI 모델을 만드는 기술이다. 이용자가 질문이나 명령을 하면 AI 모델 전체가 아니라 그중 금융·법률 등 관련된 분야 전문가만 나서서 작업을 수행한다. 모델 전체가 모든 작업에 동원되는 기존 대형언어모델(LLM)보다 연산 비용을 줄일 수 있다.

SK텔레콤은 최근 MoE 모델의 ‘전문가 활성화 불균형’을 개선한 연구성과를 공개했다. MoE는 이용자 질문·명령별 가장 적합한 전문가를 불러내는 ‘라우팅’ 과정이 필요하다. 라우팅이 제대로 이뤄지지 않으면 특정 전문가만 자주 불려나가 일하고 나머지 전문가는 방치된다. 이에 오히려 LLM보다 비효율적일 수 있는 문제를 SK텔레콤 연구진이 개선했다는 것이다.
KT도 이달 초 LLM ‘믿음 2.0’을 공개하며 “향후 MoE 구조 같은 대규모 모델 아키텍처 확장과 학습 효율성 연구를 지속할 계획”이라며 MoE 모델 개발 방침을 밝혔다. 카카오는 24일 국내 최초 오픈소스(개방형) MoE 모델 ‘카나나-1.5-15.7B-A3B’를 공개하며 주도권 확보에 나섰다. 이 모델이 기존 모델보다 2~3배 적은 파라미터(자원)만으로 더 높은 추론 연산을 할 수 있다는 설명이다. LG AI연구원은 앞서 AI 서비스 ‘챗엑사원’에 MoE 기법을 적용했다. ‘엑사원’ 모델 자체는 MoE가 아니지만 이 모델 여러 개를 각각의 전문가로 만들어 이용자가 MoE처럼 쓸 수 있게 구현한 것이다.
현재 중국은 올 초 딥시크가 MoE 모델을 선보인 후 최근 ‘제2의 딥시크’로 주목받는 문샷AI ‘키미 K2’도 등장하는 등 주도권 경쟁에 적극적이다. 미국에서는 딥마인드가 지난해 전문가 수백만 개를 구현할 수 있는 기술 ‘피어(PEER)’, IBM은 올 초 MoE 모델 연산에 특화한 AI 칩 개발 성과를 발표했다.
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >
 sookim@sedaily.com
sookim@sedaily.com