





정보기술(IT) 시장에 관심 많으신 독자 여러분, 안녕하세요. 삼성전자가 지난 20일 주주총회에서 상당히 흥미로운 발표를 했죠. 인공지능(AI) 추론 칩 마하1을 개발한다는 소식이었는데요. 경계현 삼성전자 반도체(DS)부문 사장은 "내년에 마하1을 중심으로 한 새로운 AI 시스템을 선보일 것"이라고 의미심장하게 이야기했습니다.

삼성전자가 개발하는 이 반도체는 데이터센터용 AI 추론 칩으로 알려졌는데요. 간단히 개요를 말씀드리면요. 마하1은 엔비디아의 그래픽처리장치(GPU) 대체를 목표로 하는 NPU 칩입니다. NPU가 GPU 등 별도의 AI 가속 칩과 결합하지 않습니다. 독립적으로 움직이는 AI 추론용 SoC입니다. 이 SoC와 같이 움직이는 메모리 부분도 독특합니다. 통상 AI 칩은 HBM과 결합하는데, 마하1은 범용 D램인 LPDDR 메모리를 쓰는 것이 특징입니다.
그럼 왜 AI 칩을 개발하게 된 걸까. 어떤 방식으로 AI 칩 최강자 엔비디아의 아성에 도전하고 있을까. 네이버와는 '마하1'의 어떤 분야에서 협력하고 있을까. 오늘은 마하1을 개발하고 있는 엔지니어들의 아이디어를 따라가보려고 합니다.
'마하1' 속을 들여다보기 위해 총 세가지 키워드로 준비했습니다. ①경량화 ②압축 ③LPDDR로 나눠서 준비했습니다. 총 2편으로 나눕니다. 우선 경량화부터 천천히 들어가봅시다.
①경량화
경량화(輕量化). 물건이나 규모 등이 이전보다 줄거나 가벼워진다는 뜻이죠. 삼성전자는 마하1에서 데이터를 경량화하겠다는 콘셉트를 잡았습니다. 똑같은 데이터라도 기존보다 군살을 빼거나 형태를 가볍게 한다는 이야기죠.
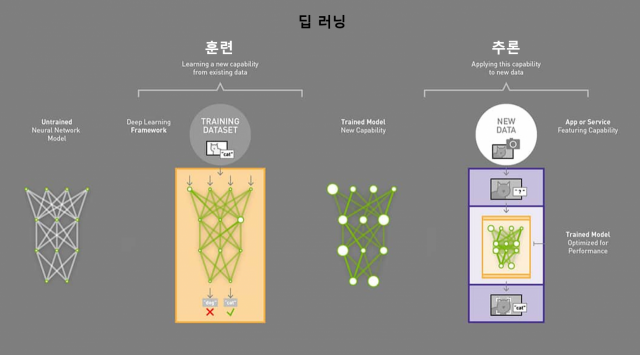
그럼 왜 데이터를 경량화하는 건가. 인공지능(AI) 시대는 한마디로 데이터 전쟁입니다. AI는 수많은 데이터를 입력해 '훈련'을 한 다음, 그 결과를 토대로 마치 사람처럼 '추론'하는 과정으로 진행됩니다. AI 시스템은 귀납적인 사고를 하기 때문에 학습한 데이터가 많을수록 정확해지고, 그래서 정보가 쌓일수록 추론의 과정 역시 복잡해집니다. 거대언어모델(LLM) AI용 데이터센터가 수많은 GPU나 CPU, AI용 연산 장치를 설치해 놓는 이유이기도 합니다.
그런데 문제는 데이터 병목현상과 전력입니다. 우선 병목 현상. 날이 갈수록 데이터가 늘어나자 정보가 메모리-AI 칩 사이를 원활하게 오가도록 정보출입구(I/O) 수를 대폭 늘린 HBM이 개발됐죠. 그래도 병목현상이 쉽게 해결되지 않습니다. 이미 연산 장치와 HBM 사이에 1000개가 넘는 I/O가 깔렸고 향후 이것이 앞으로 2배나 더 늘어날 것으로도 예상되지만 교통체증이 해결될만한 수준이 아니기에 AI 연구자들은 애를 태우죠.

가장 심각한 문제는 전력입니다. 엔비디아가 새롭게 발표한 AI 칩 B200의 소비 전력은 1000와트(W)가 넘는다고 하죠. 여러분, 노트북PC 하나의 전력 소비량이 최대 65W라고 하고요. 에어컨 한 대의 소비전력이 2000W입니다. 손바닥만한 칩 두 개 돌리는 데 에어컨 한 대 돌아가는 전력이 드는 셈이죠. 거기다 AI 데이터센터는 GPU를 한 두개 정도만 돌리지 않습니다. 메타는 올 연말까지 AI 인프라 구축을 위해 엔비디아 GPU H100을 35만 개 확보할 계획이라고 합니다.
여기다가 GPU와 메모리 사이 병목현상이 심해질수록 열이 납니다. 이 열을 식히는 쿨링 장치도 필수적이죠. 이 기기는 또 얼마나 많은 전력이 들까요. 그래서 업계에서는 "AI 데이터 센터 하나 돌리려면 원자력 발전소 하나가 필요할 정도"라는 농담이 나올 정도입니다.
가장 중요한 문제. 이 상황은 모두 돈과 연결됩니다. 엔비디아 H100의 최소 가격은 2만5000달러(3300만원). H100 속에 들어가는 HBM의 가격은 범용 D램 가격의 6~7배. 어마어마한 설비투자에 매달 폭탄 맞듯이 나오는 전기 요금에 유지비까지. 어휴. AI 한번 하려는 데 너무 많은 돈이 나가서 클라우드 서비스 업체(CSP) 경영진의 고민이 이만저만이 아닙니다.
이걸 해결하기 위해 경량화라는 말이 나옵니다. 알고리즘으로 데이터의 군살을 빼고 이 소프트웨어가 잘 동작할 수 있도록 칩 구조를 아주 영특하게 바꿔서 전력을 줄여보자는 얘기죠. 같은 데이터를 옮길 때 기존보다 더 적은 전력을 쓰거나, 지금과 같은 전력을 쓰더라도 훨씬 더 많은 데이터를 효율적으로 옮길 수 있게 된다는 겁니다. 자, 그럼 마하1에선 어떤 식으로 경량화를 위한 소프트웨어를 짜고 있는 것인지 살펴보겠습니다. 아래부터는 첫번째 압축 기술을 소개합니다.
②압축-1 : 가지치기(Pruning)
삼성전자는 데이터를 어떻게 '압축'해서 경량화할 것인가에 초점을 둔 알고리즘을 개발하고 있습니다. 먼저 대표적인 압축의 첫번째 방법인 프루닝(Pruning)에 대한 이야기를 해보겠습니다. Prune을 영어사전에서 찾아보면 '가지치기'라는 뜻을 가지고 있습니다. 나뭇가지에서 불필요한 부분을 다듬는다는 뜻이죠.
삼성의 마하1에는 이 프루닝 알고리즘이 심어져 있습니다. 데이터를 가지치기 한다는 뜻이죠. 그럼 뭘 솎아낸다는 걸까. AI 메모리 안에는요. 어떤 입력값을 원하는 출력값으로 만들기 위해서 가공을 하는 매개변수, 이른바 파라미터(parameter)라는 게 저장돼 있는데요. AI의 발전으로 파라미터 수가 늘고 있습니다. 메모리에서 GPU로 이동하는 터널이 맨날 이 파라미터 때문에 막히고 열이 난다고 해도 과언이 아니죠.
그래서 메모리 안에서는 극심한 교통 체증을 해결하기 위해 가지치기를 합니다. 이 파라미터는 꾸러미 형태로 저장돼 있는 게 특징입니다. 파라미터 꾸러미 전체를 GPU로 냅다 던지는 게 아니고요. 꾸러미 속에서 '굳이 이 연산에 필요하지 않겠다' 싶은 것들은 빼고 전달을 한다는 거죠. 맞습니다. 프루닝입니다.
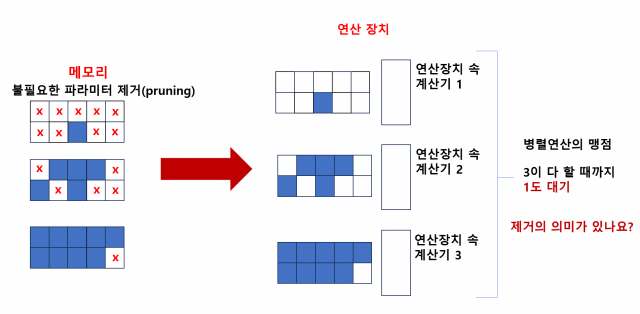
여기까지는 그럴싸합니다. 그런데 문제가 있습니다. 각 꾸러미마다 가지쳐내고 남은 파라미터 개수가 다르다는 건데요. 예를 들어 10개 파라미터가 한 묶음인 꾸러미가 있다 친다면요. 어떤 건 1개만 남기고 모든 것을 가지치기한 꾸러미가 있을 것이고, 또 어떤 건 9개나 살린 꾸러미가 있을 수 있다는 얘기입니다.
이들이 GPU에 전달되면서 문제가 발생합니다. GPU는 병렬 연산이 큰 특징이죠. 쏟아지는 데이터를 수많은 일꾼들이 한 번에 계산할 수 있다는 게 특징입니다.
이게 단점으로 작용하기도 합니다. 1개 파라미터만 담긴 꾸러미를 연산하면 되는 GPU 속 계산 장치가 연산을 끝냈다고 하더라도요. 9개 살아남은 꾸러미가 모든 계산을 마칠 때까지 기다려야 한다는 겁니다. 9개 파라미터를 계산하느라 허덕이는 것을 보는 옆 친구의 불안한 눈빛, 계산이 끝날 때까지 눈치보며 낮잠자고 있는 고연봉의 HBM. 비효율의 끝입니다.
삼성전자, 마하1을 함께 개발 중인 네이버 반도체 개발팀은 프루닝의 문제를 해결하기 위해 한 발 더 나갔습니다.
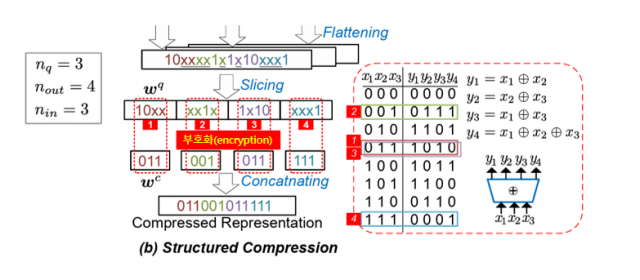
이른바 암호화 알고리즘(encryption)으로 정보를 변환하는 아이디어를 얻어서요. 9개가 제거된 꾸러미를 3개로, 단 1개만 제거된 파라미터 꾸러미도 3개의 일정한 코드로 변환을 해서 아주 구조적이고(structured) 일정한 형태로 만드는 거죠. 이렇게 되면 연산 장치 속 계산기들은 균일하게 잘 다듬어진 파라미터 꾸러미를 비교적 동일한 시간에 빠르게 연산할 수 있을 것입니다. 데이터 경량화 실현으로 인터페이스의 병목현상이 줄고 테이블 순환율이 빠른 식당처럼 아주 효율적인 AI 연산이 가능하다는 거죠.

삼성전자는 낸드플래시가 장착된 정보 기억 장치 SSD에서 이 아이디어를 얻은 것으로 취재됐습니다. SSD에서는 저장돼 있는 정보의 오류를 판별하고 수정하는 ECC(Error Correction Code)라는 게 있는데요. 이게 임의의 코드를 입력하는 암호화(부호화)와 복호화 알고리즘이 적용됩니다. 5G 등 고속이동통신에서 정보 오류를 잡을 때도 ECC가 아주 잘 쓰인다고 합니다.
또한 실제 2020년 삼성리서치에서는 프루닝과 데이터 압축·부호화에 대한 기술 논문을 냈는데, 이때 연구됐던 알고리즘이 마하1에 응용됐을 가능성이 있습니다. 네이버 역시 이 알고리즘의 가능성을 보고 삼성전자와 열심히 개발하고 있는 것으로 보입니다.
2편에서는 두번째 압축 알고리즘인 양자화 기술, 세번째 파트인 LPDDR D램을 마하1에 어떻게 적용할 수 있는지에 대해 알아보려고 합니다. 즐거운 주말 보내세요!
< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >






































